Raft 集群成员变更
在前面三个章节中,我们介绍了Raft的:
上面的讨论都是基于Raft集群成员恒定不变的,然而在很多时候,集群的节点可能需要进行维护,或者是因为需要扩容,那么就难以避免的需要向Raft集群中添加和删除节点。最简单的方式就是停止整个集群,更改集群的静态配置,然后重新启动集群,但是这样就丧失了集群的可用性,往往是不可取的,所以Raft提供了两种在不停机的情况下,动态的更改集群成员的方式:
- 单节点成员变更:
One Server ConfChange - 多节点联合共识:
Joint Consensus
动态成员变更存在的问题
在Raft中有一个很重要的安全性保证就是只有一个Leader,如果我们在不加任何限制的情况下,动态的向集群中添加成员,那么就可能导致同一个任期下存在多个Leader的情况,这是非常危险的。
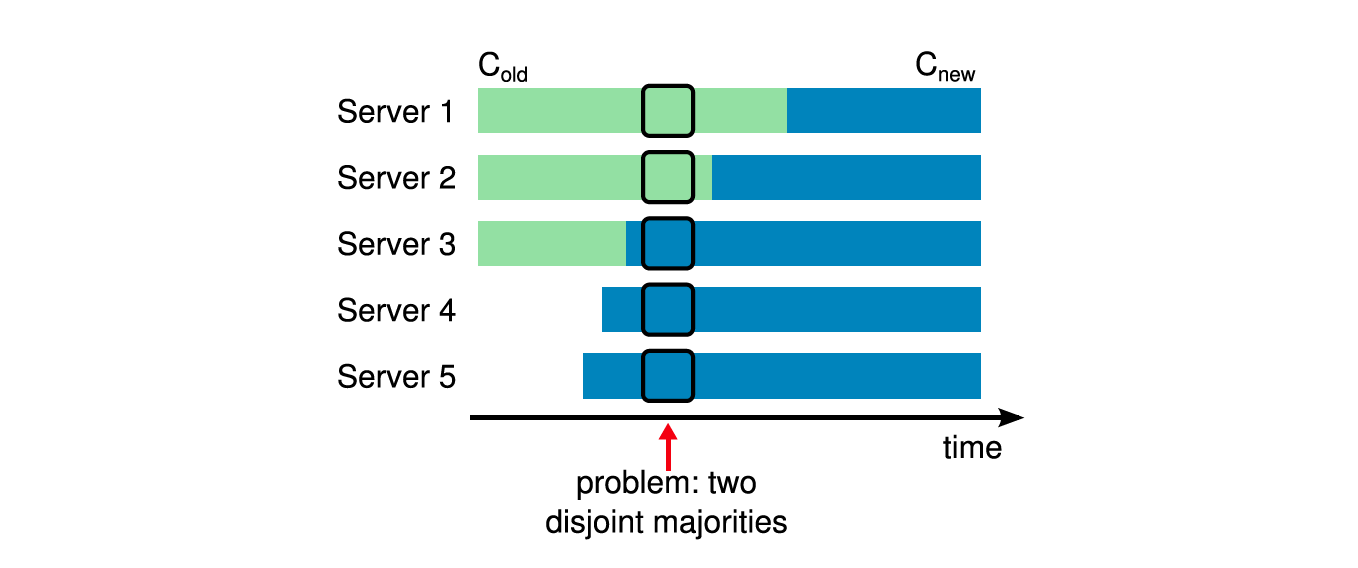
如下图所示,从Cold迁移到Cnew的过程中,因为各个节点收到最新配置的实际不一样,那么肯能导致在同一任期下多个Leader同时存在。
比如图中此时Server3宕机了,然后Server1和Server5同时超时发起选举:
- Server1:此时Server1中的配置还是Cold,只需要Server1和Server2就能够组成集群的Majority,因此可以被选举为Leader
- Server5:已经收到Cnew的配置,使用Cnew的配置,此时只需要Server3,Server4,Server5就可以组成集群的Majority,因为可以被选举为Leader
换句话说,以Cold和Cnew作为配置的节点在同一任期下可以分别选出Leader。
所以为了解决上面的问题,在集群成员变更的时候需要作出一些限定。
单节点成员变更
所谓单节点成员变更,就是每次只想集群中添加或移除一个节点。比如说以前集群中存在三个节点,现在需要将集群拓展为五个节点,那么就需要一个一个节点的添加,而不是一次添加两个节点。
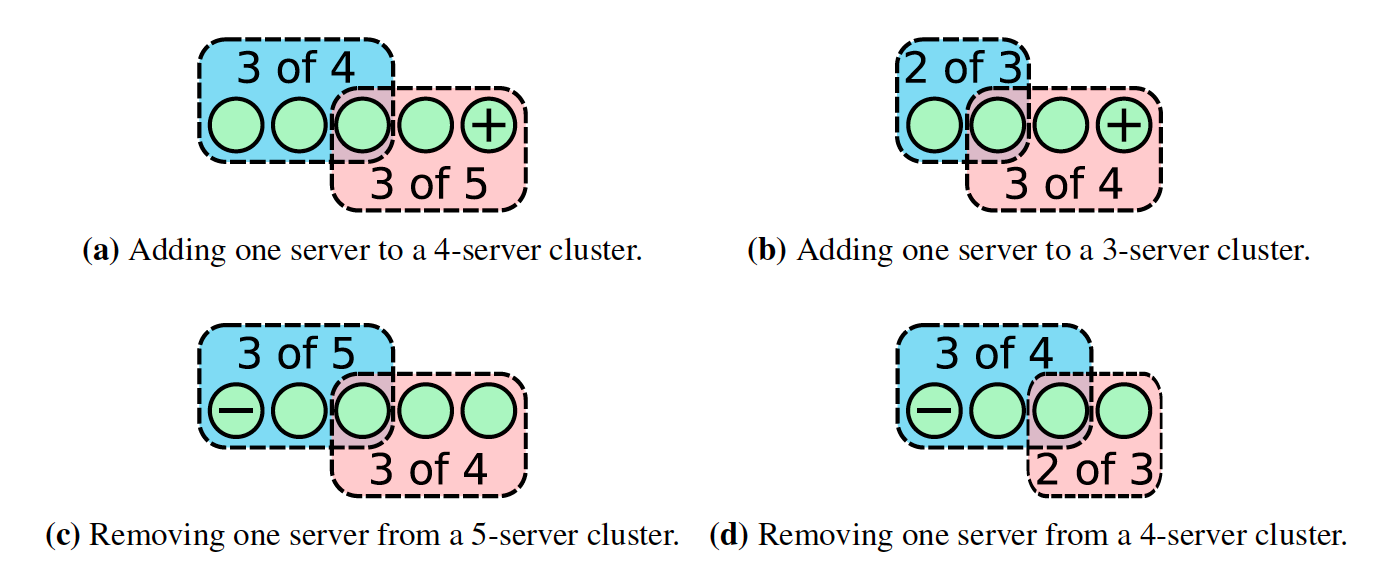
这个为什么安全呢?很容易枚举出所有情况,原有集群奇偶数节点情况下,分别添加和删除一个节点。在下图中可以看出,如果每次只增加和删除一个节点,那么Cold的Majority和Cnew的Majority之间一定存在交集,也就说是在同一个Term中,Cold和Cnew中交集的那一个节点只会进行一次投票,要么投票给Cold,要么投票给Cnew,这样就避免了同一Term下出现两个Leader。
变更的流程如下:
- 向Leader提交一个成员变更请求,请求的内容为服务节点的是添加还是移除,以及服务节点的地址信息
- Leader在收到请求以后,回向日志中追加一条
ConfChange的日志,其中包含了Cnew,后续这些日志会随着AppendEntries的RPC同步所有的Follower节点中 - 当
ConfChange的日志被添加到日志中是立即生效(注意:不是等到提交以后才生效) - 当
ConfChange的日志被复制到Cnew的Majority服务器上时,那么就可以对日志进行提交了
以上就是整个单节点的变更流程,在日志被提交以后,那么就可以:
- 马上响应客户端,变更已经完成
- 如果变更过程中移除了服务器,那么服务器可以关机了
- 可以开始下一轮的成员变更了,注意在上一次变更没有结束之前,是不允许开始下一次变更的
可用性
可用性问题
在我们向集群添加或者删除一个节点以后,可能会导致服务的不可用,比如向一个有三个节点的集群中添加一个干净的,没有任何日志的新节点,在添加节点以后,原集群中的一个Follower宕机了,那么此时集群中还有三个节点可用,满足Majority,但是因为其中新加入的节点是干净的,没有任何日志的节点,需要花时间追赶最新的日志,所以在新节点追赶日志期间,整个服务是不可用的。
在接下来的子章节中,我们将会讨论三个服务的可用性问题:
- 追赶新的服务器
- 移除当前的Leader
- 中断服务器
追赶新的服务器
在添加服务器以后,如果新的服务器需要花很长时间来追赶日志,那么这段时间内服务不可用。
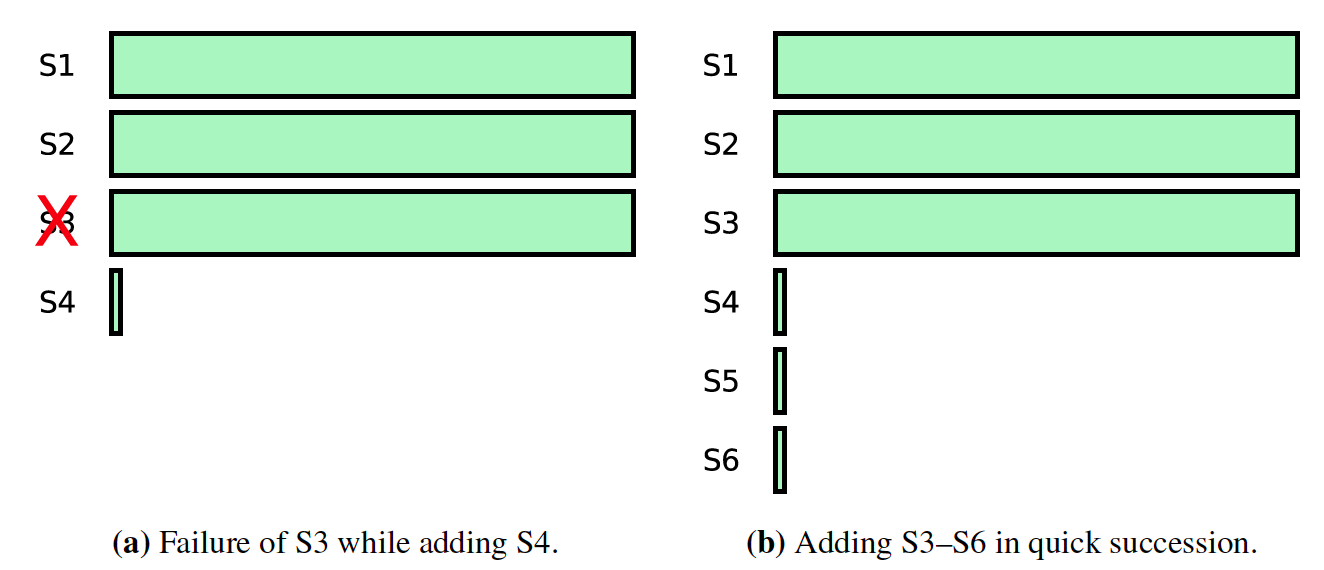
如下图所示:
- 左图:向集群中添加新的服务器S4以后,S3宕机了,那么此时因为S4需要追赶日志,此时不可用
- 右图:向集群中添加多个服务器,那么添加以后Majority肯定是包含新的服务器的,那么此时S4,S5,S6需要追赶日志,肯定也是不可用的
新加入集群中的节点可能并不是因为需要追赶大量的日志而不可用,也有可能是因为网络不通,或者是网速太慢,导致需要花很长的时间追赶日志。
在Raft中提供了两种解决方案:
- 在集群中加入新的角色
Leaner,Leaner只对集群的日志进行复制,并不参加投票和提交决定,在需要添加新节点的情况下,添加Leaner即可。 - 加入一个新的Phase,这个阶段会在固定的Rounds(比如10)内尝试追赶日志,最后一轮追赶日志的时间如果小于
ElectionTimeout, 那么说明追赶上了,否则就抛出异常
下面我们就详细讨论一下第二种方案。
在固定Rounds内追赶日志
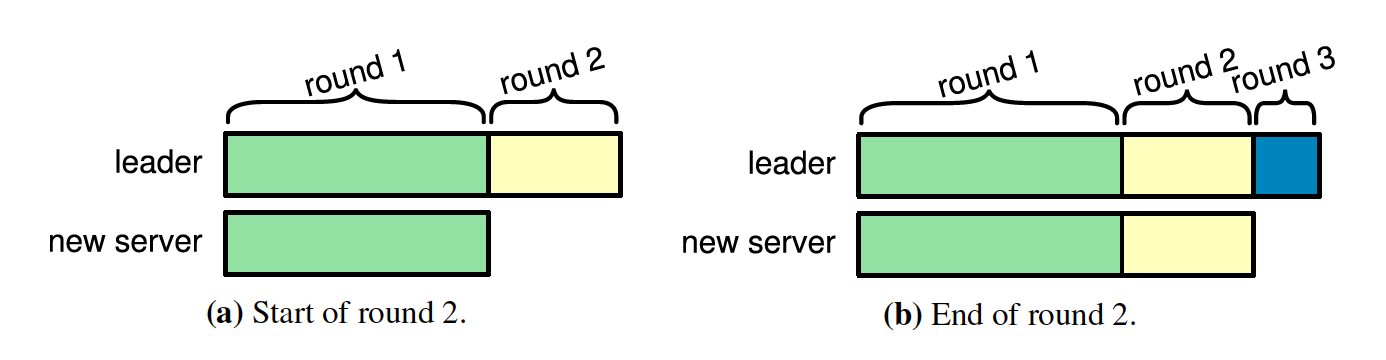
如果需要添加的新的节点在很短时间内可以追赶上最新的日志,那么就可以将该节点添加到集群中。那要怎么判断这个新的节点是否可以很快时间内追赶上最新的日志呢?
Raft提供了一种方法,在配置变更之前引入一个新的阶段,这个阶段会分为多个Rounds(比如10)向Leader同步日志,如果新节点能够正常的同步日志,那么每一轮的日志同步时间都将缩短,如果在最后一轮Round同步日志消耗的时间小于ElectionTimeout,那么说明新节点的日志和Leader的日志已经足够接近,可以将新节点加入到集群中。但是如果最后一轮的Round的日志同步时间大于ElectionTimeout,就应该立即终止成员变更。
移除当前的Leader
如果在Cnew中不包含当前的Leader所在节点,那么如果Leader在收到Cnew配置以后,马上退位成为Follower,那么将会导致下面的问题:
ConfChange的日志尚未复制到Cnew中的大多数的节点- 马上退位成为Follower的可能因为超时成为新的Leader,因为该节点上的日志是最新的,因为日志的安全性,该节点并不会为其他节点投票
为了解决以上的问题,一种很简单的方式就是通过Raft的拓展Leadership transfer首先将Leader转移到其他节点,然后再进行成员变更,但是对于不支持Leadership transfer的服务来说就行不通了。
Raft中提供了一种策略,Leader应该在Cnew日志提交以后才退位。
中断的服务器
如果Cnew中移除了原有集群中的节点,因为被移除的节点是不会再收到心跳信息,那么将会超时发起一轮选举,将会造成当前的Leader成为Follower,但是因为被移除的节点不包含Cnew的配置,所以最终会导致Cnew中的部分节点超时,重新选举Leader。如此反反复复的选举将会造成很差的可用性。
一种比较直观的方式是采用Pre-Vote方式,在任何节点发起一轮选举之前,就应该提前的发出一个Pre-Vote的RPC询问是否当前节点会同意给当前节点投票,如果超过半数的节点同意投票,那么才发生真正的投票流程的,有点类似于Two-Phase-Commit,这种方式在正常情况下,因为被移除的节点没有包含Cnew的ConfChange日志,所以在Pre-Vote情况下,大多数节点都会拒绝已经被移除节点的Pre-Vote请求。
但是上面只能处理大多数正常的情况,如果Leader收到Cnew的请求后,尚未将Cnew的ConfChange日志复制到集群中的大多数,Cnew中被移除的节点就超时开始选举了,那么Pre-Vote此时是没有用的,被移除的节点仍有可能选举成功。顺便一说,这里的Pre-Vote虽然不能解决目前的问题,但是针对脑裂而产生的任期爆炸式增长和很有用的,这里就不展开讨论了。
就如下图所示,S4收到Cnew成员变更的请求,立马将其写入日志中,Cnew中并不包含S1节点,所以在S4将日志复制到S2,S3之前,如果S1超时了,S2,S3中因为没有最新的Cnew日志,仍让会投票给S1,此时S1就能选举成功,这不是我们想看到的。
Raft中提供了另一种方式来避免这个问题,如果每一个服务器如果在ElectionTimeout内收到现有Leader的心跳(换句话说,在租约期内,仍然臣服于其他的Leader),那么就不会更新自己的现有Term以及同意投票。这样每一个Follower就会变得很稳定,除非自己已经知道的Leader已经不发送心跳给自己了,否则会一直臣服于当前的leader,尽管收到其他更高的Term的服务器投票请求。
任意节点的Joint Consensus
上面我们提到单节点的成员变更,很多时候这已经能满足我们的需求了,但是有些时候我们可能会需要随意的的集群成员变更,每次变更多个节点,那么我们就需要Raft的Joint Consensus, 尽管这会引入很多的复杂性。
Joint Consensus会将集群的配置转换到一个临时状态,然后开始变更:
- Leader收到Cnew的成员变更请求,然后生成一个Cold,new的ConfChang日志,马上应用该日志,然后将日志通过
AppendEntries请求复制到Follower中,收到该ConfChange的节点马上应用该配置作为当前节点的配置 - 在将Cold,new日志复制到大多数节点上时,那么Cold,new的日志就可以提交了,在Cold,new的ConfChange日志被提交以后,马上创建一个Cnew的ConfChange的日志,并将该日志通过
AppendEntries请求复制到Follower中,收到该ConfChange的节点马上应用该配置作为当前节点的配置 - 一旦Cnew的日志复制到大多数节点上时,那么Cnew的日志就可以提交了,在Cnew日志提交以后,就可以开始下一轮的成员变更了
为了理解上面的流程,我们有几个概念需要解释一下:
Cold,new:这个配置是指Cold,和Cnew的联合配置,其值为Cold和Cnew的配置的交集,比如Cold为[A, B, C], Cnew为[B, C, D],那么Cold,new就为[A, B, C, D]Cold,new的大多数:是指Cold中的大多数和Cnew中的大多数,如下表所示,第一列因为Cnew的C, D没有Replicate到日志,所以并不能达到一致
| Cold | Cnew | Replicate结果 | 是否是Majority |
|---|---|---|---|
| A, B, C | B, C, D | A+, B+, C-, D- | 否 |
| A, B, C | B, C, D | A+, B+, C+, D- | 是 |
| A, B, C | B, C, D | A-, B+, C+, D- | 是 |
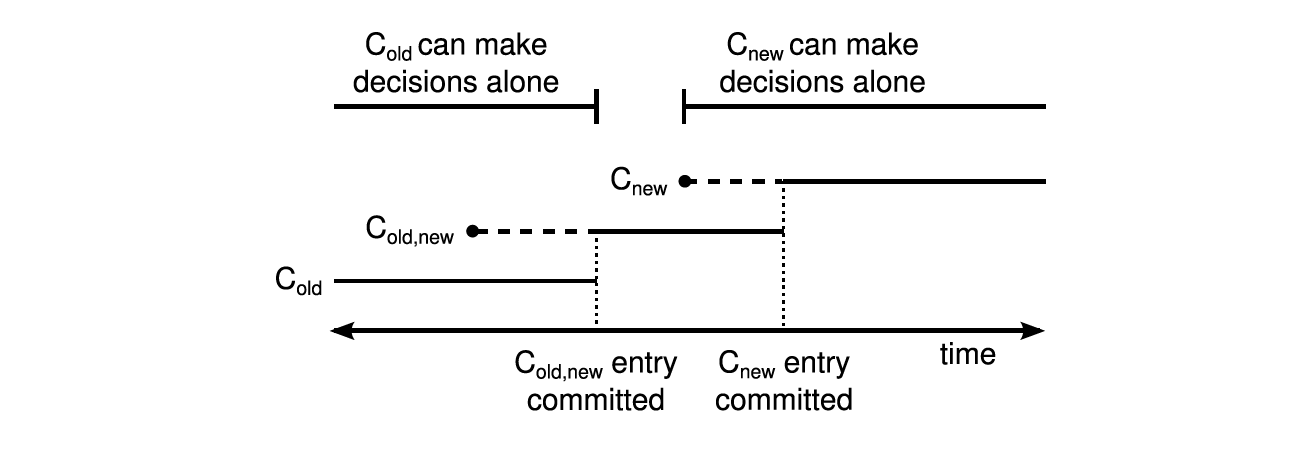
由上可以看出,整个集群的变更分为几个过渡期,就如下图所示,在每一个时期,每一个任期下都不可能出现两个Leader:
- Cold,new日志在提交之前,在这个阶段,Cold,new中的所有节点有可能处于Cold的配置下,也有可能处于Cold,new的配置下,如果这个时候原Leader宕机了,无论是发起新一轮投票的节点当前的配置是Cold还是Cold,new,都需要Cold的节点同意投票,所以不会出现两个Leader
- Cold,new提交之后,Cnew下发之前,此时所有Cold,new的配置已经在Cold和Cnew的大多数节点上,如果集群中的节点超时,那么肯定只有有Cold,new配置的节点才能成为Leader,所以不会出现两个Leader
- Cnew下发以后,Cnew提交之前,此时集群中的节点可能有三种,Cold的节点(可能一直没有收到请求), Cold,new的节点,Cnew的节点,其中Cold的节点因为没有最新的日志的,集群中的大多数节点是不会给他投票的,剩下的持有Cnew和Cold,new的节点,无论是谁发起选举,都需要Cnew同意,那么也是不会出现两个Leader
- Cnew提交之后,这个时候集群处于Cnew配置下运行,只有Cnew的节点才可以成为Leader,这个时候就可以开始下一轮的成员变更了
其他
自动的成员变更
如果我们给集群增加一些监控,比如在检测到机器宕机的情况下,动态的向系统中增加新的节点,这样就可以做到自动化,增加系统的节点数。
集群动态配置
一般情况下,我们都是使用静态文件的方式来描述集群中的成员信息,但是有了成员变更的算法,我们就可以动态配置的方式来设置集群的配置信息