Raft 算法之日志复制
Raft 论文地址:https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf
Raft论文中分为三块:
- 领导选举
- 日志复制
- 安全性
本文中主要介绍日志复制
领导人必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
鉴于日志复制这一块比较复杂,可以结合下面两个网页来理解:
- http://thesecretlivesofdata.com/raft/
- https://raft.github.io/
复制状态机
复制状态机通常都是基于复制日志实现的,每一个服务器存储一个包含一系列指令的日志,并且按照日志的顺序进行执行。如下图所示:
- 客户端请求服务器,请求的信息就是一系列的指明,比如
PUT KEY VALUE - 服务器在收到请求以后,将操作指令同步到所有的服务器中
- 服务器收到同步的指令以后,就将指令应用到状态机中
- 最后响应客户端操作成功
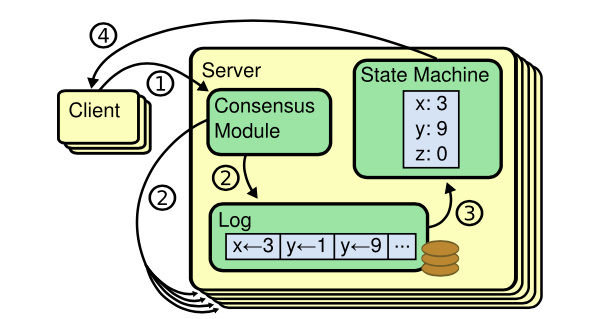
状态机是按照同步到服务器上的指令的顺序,一个一个的去Apply指令,所以指令的顺序很重要,如果指令Apply的顺序不一致,或者丢失部分指令,那么最终状态机的状态也会不一致。
而我们知道网络是不稳定的,比如延迟,分区,丢包,荣誉和乱序等错误。如果不保证状态机Apply指令完全一模一样,那么将会导致不一致的结果。而Raft的日志复制机制则能保证在发生上述网络问题的时候,所有的服务器都能同步到完全一模一样的日志,也就是说能保证每一个服务器的状态机Apply到完全一模一样的指令。
附加日志RPC
请求体结构
所有服务器上都维持的状态:
commitIndex:最大的已经被提交的日志索引lastApplied:最后被应用到状态的日志条目索引
lastApplied应该小于等于commitIndex,因为只有在日志被提交以后才能被Apply到状态机中
领导人经常改变的:
nextIndex[]:对于每一个服务器,需要发送给他的下一个日志条目的索引值,初始化为当前领导人的最后的日志索引值加一matchIndex[]:对于每一个服务器,已经复制给他的日志的最高索引值
nextIndex[] 和 matchIndex[]的长度等于整个集群中的服务器数量。
附加日志RPC的请求结构:
term:附加日志的领导人任期号leaderId:当前领导人的IdpreLogIndex:当前要附加的日志entries的上一条的日志索引preLogTerm:当前要附加的日志entries的上一条的日志任期号entries[]:需要附加的日志条目(心跳时为空)leaderCommit:当前领导人已经提交的最大的日志索引值
preLogIndex和preLogTerm主要是用于跟随者检测当前领导人要附加的日志是否和跟随者当前的日志匹配,如果不匹配的话,那么就需要继续向前搜寻和领导人匹配的日志(下面章节会介绍)
而leaderCommit的话用于告诉跟随者当前提交到什么位置了(因为收到附加日志还不能马上提交,否则可能存在日志丢失的情况),以便跟随者将已经提交的日志Apply到状态机中
附加日志RPC的响应结构:
term:跟随者的当前的任务号success:跟随者是否接收了当前的日志,在preLogIndex和preLogTerm匹配的情况下为true,否则返回false
请求的流程
每一个日志条目存储一条状态机指令和从领导人收到这条指令时的任期号。日志中的任期号用来检查是否出现不一致的情况,每一条日志条目同时也都有一个整数索引值来表明它在日志中的位置。
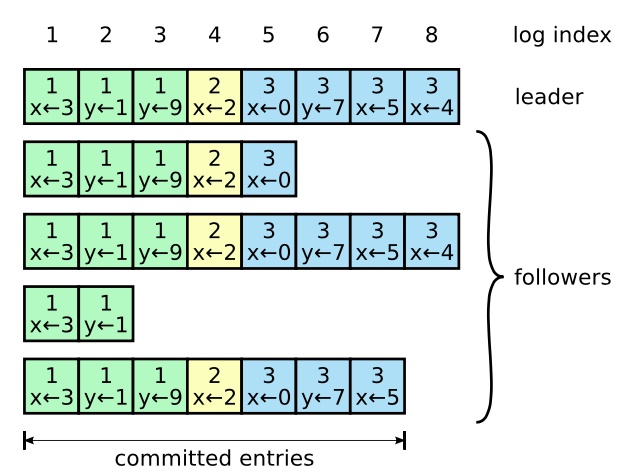
领导人附加日志
一旦成为领导人,那么领导人就会在固定在一定时间内发送空的附加日志,也就是心跳,以组织更随着超时。
如果领导人收到来自己客户端的请求,那么首先将请求的指令附加到自己的日志队列中,然后领导人会将新附加的日志条目通过附加日志的RPC发送到所有的跟随者。
领导人需要附加那些日志?
领导人中维护了两个经常变动的属性nextIndex[]和matchIndex[],用于记录要发什么日志和跟随者收到了什么日志。
其中nextIndex[]记录了需要发送给每一个服务器的日志的下一个索引值,这个数组会在领导人被选举出来的时候初始化为领导人最后的索引加一。注意这个nextIndex[]只是记录了要发给下一次附加日志要发给服务器的索引值,这个索引值可能并不一定准确,比如在跟随者和领导人的日志不一致的情况下,nextIndex[]的值就需要进行递减以找到和跟随者最大的匹配的日志,具体流程后文中会解释。
而matchIndex[]主要是用来记录跟随者收到了那些日志,以方便领导人确认是否当前的日志可以进行提交,因为必须要至少N/2+1的集群成员(包括领导人自己)都确认收到了日志才可以进行的日志的提交。
领导人收到收到跟随者附加日志的响应该如何处理?
我们知道领导人在附加日志的时候是并发的向所有跟随者发起的,并且是在固定周期内定时发送的,所以可能在上一个RPC没有收到响应的情况下,发出下一个RPC请求,或者是收到过期的日志追加请求等等。
- 比对响应的
Term和当前的Term以确认自己是否过期:- 如果响应的
Term大于当前的Term,那么说明当前的领导人已经过期,马上将自己切换为跟随者 - 如果响应的
Term小于当前的Term,那么说明当前的收到了过期的响应(可能网路延迟导致),那么忽略 - 否则进行步骤2
- 如果响应的
- 判断附加RPC时的
preLogIndex和当前的nextIndex[peer]-1是否相等,用于判断是否是过期的响应,或者是nextIndex[peer]是否被更改了:- 如果不相等,那么直接忽略
- 否则进行步骤3
- 判断响应的
success是否为真:- 如果为真:那么说明附加日志成功,进行步骤4
- 如果为假:那么说明附加日志失败,
preLogIndex和preLogTerm和跟随者的日志不匹配,进行步骤5
- 附加日志成功以后,需要更新
matchIndex[peer]中的值为已经追加日志的索引值,表示追加日志成功,判断整个matchIndex[]数组中的是否有一半都大于等于追加日志的索引:- 如果是:那么更新
commitIndex,进行日志的提交 - 否则跳过处理
- 如果是:那么更新
- 日志不匹配,那么需要找到下一个和跟随者匹配的日志索引,简单一点可以通过递减
nextIndex[peer]来实现。
跟随者接收日志
跟随者收到附加日志的请求,不能简单的将日志追加到自己的日志后面,因为跟随者的日志可能和领导人有冲突,或者跟随者缺失更多的日志,入下图所示。
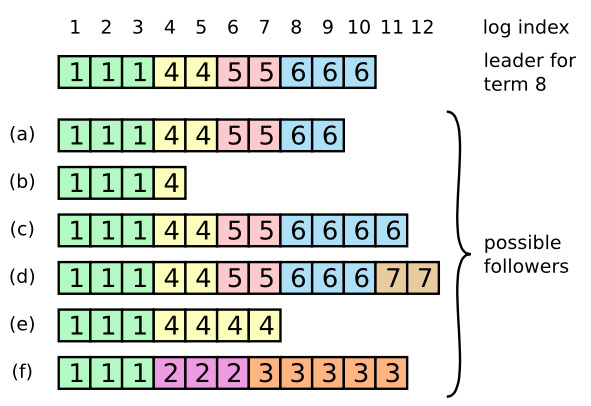
那么一定要确保本次附加日志的之前的所有日志都相同,也就是说附加当前的日志之前,缺日志就要把缺失的日志补上,日志冲突了,就要把冲突的日志覆盖(领导人可以强行覆盖跟随者的日志)
- 判断附加日志任期
Term和当前的Term是否相同:- 如果请求的
Term小于当前的Term,那么说明收到了来自过期的领导人的附加日志请求,那么拒接处理。 - 如果请求的
Term大于当前的Term,那么更新当前的Term为请求的Term,进行步骤2 - 如果请求的
Term和当前的Term相等,那么说明请求合法,进行步骤2
- 如果请求的
- 判断
preLogIndex是否大于当前的日志长度或者preLogIndex位置处的任期是否和preLogTerm相等以检测要附加的日志之前的日志是否匹配:- 如果
preLogIndex的长度大于当前的日志的长度,那么说明跟随者缺失日志,那么拒绝附加日志,返回false - 如果
preLogIndex处的任期和preLogTerm不相等,那么说明日志有冲突,拒绝附加日志,返回false - 否则说明之前的日志全都匹配,那么进行步骤3,检测
preLogIndex之后的日志是否匹配。
- 如果
- 逐一比对要附加的日志
entries[]是否和自己preLogIndex之后的日志是否有冲突:- 如果
entries[]中的任何一位置的日志发生冲突,那么需要将之后的日志进行截断,并追加为entries[]中之后的日志 - 如果没有发生冲突,那么存在两种情况:
- 跟随者的日志和
entries[]的日志全部匹配,这种情况可能是重复的附加日志RPC,那么这种情况只会简单的校验一遍所有日志 entries[]的日志匹配当前的所有日志,那么将没有匹配的日志全都追加到当前的日志后面。
- 跟随者的日志和
- 如果
上述的步骤3是很重要的,如果不对现有的日志进行比对,而且简单的进行截断追加日志,那么是很危险,因为可能收到延时的重复日志附加请求而导致日志不必要的截断,从而导致已经提交的日志丢失。
另外还有一个优化点,如果存在大量的冲突日志,那么如果通过递减nextIndex[peer]将会很慢,所以可以通过批量跳过冲突日志方式来做到,可以再响应中添加conflictIndex和conflictTerm来做到,这里不展开详细讨论。
日志的提交和应用
所有的服务器都有两个经常变动的值commitIndex和lastApplied,commitIndex表示已经提交的日志索引,而lastApplied表示最后Apply到状态机中的日志索引。commtiIndex会在日志成功附加到集群中的N/2+1的节点上更新。
一般应用日志到状态机中是通过一个独立的线程来做到的,通过监控是否有新提交的日志,如果有新提交的日志,那么就将日志Apply到状态机中,并且更新lastApplied。所以一般commitIndex >= lastApplied
在实际的应用中,一般将Raft单独作为独立的一层共识模块,上层模块将需要达到共识的指令下发给Raft共识模块,在Raft模块达到共识以后,就将达成共识的指令Apply到上层模块中。比如Etcd,TiKV等等